UvA’ers kunnen met data corona-opnames per gemeente voorspellen

Een groep medici van het Amsterdam UMC heeft een applicatie gebouwd waarin je het verloop van het aantal infecties over de tijd per gemeente kunt volgen. Ook voorspelt het of dat aantal de komende dagen zal oplopen. ‘Dit misten we nog in Nederland: een overzicht van alle corona-gegevens. Je kunt hiermee bijvoorbeeld bekijken waarom het virus in een bepaalde gemeente meer toeslaat dan in andere.’
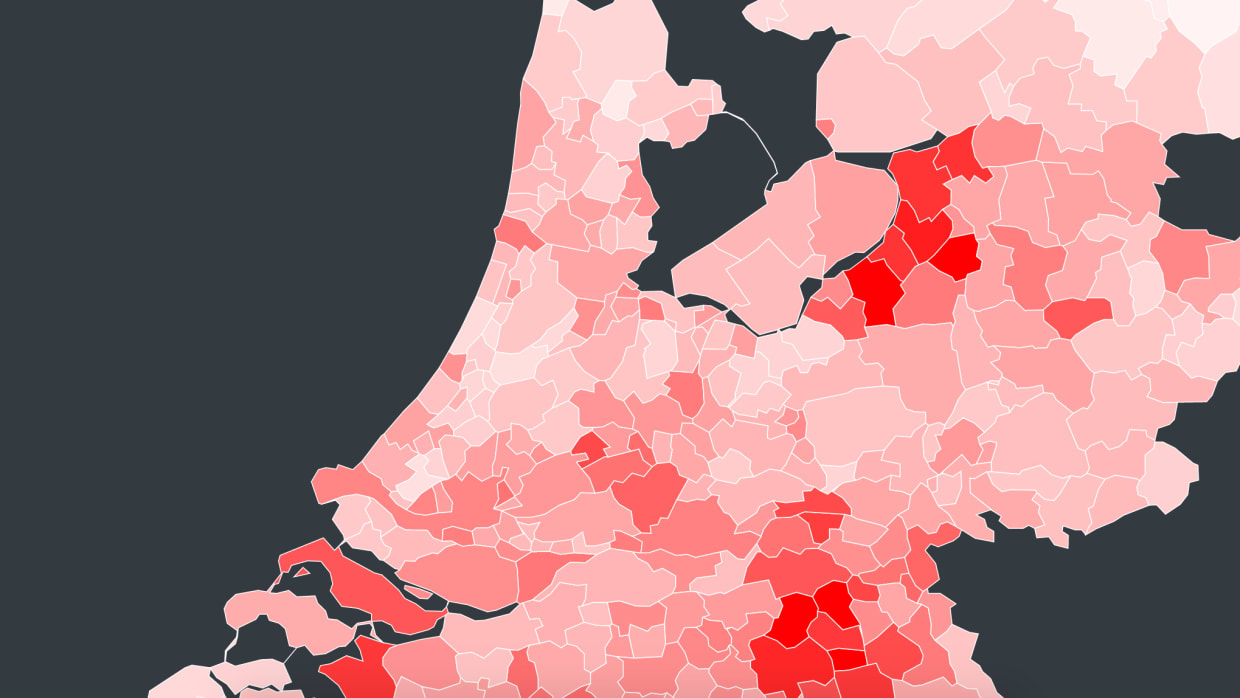
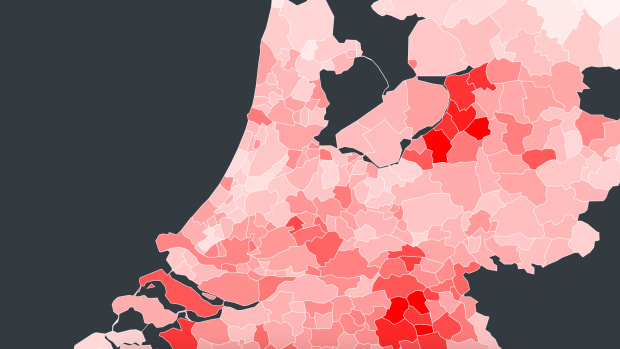
Onderzoeksgroep Dynamo heeft onder leiding van drie medische specialisten van het Amsterdam UMC, locatie AMC, een applicatie samengesteld die per gemeente allerlei coronastatistieken weergeeft, zoals het totaal aantal infecties, ziekenhuisopnames en overledenen. De applicatie, Windfall genaamd, bestaat uit een interactieve kaart waarbij je de statistieken van verschillende gemeenten kunt aanklikken en met elkaar kunt vergelijken. Ook kun je zien hoe het coronavirus zich in de afgelopen maanden als een olievlek over heel Nederland verspreidde.
Alexander Vlaar is samen met Bart Geerts en Denise Veelo verantwoordelijk voor Dynamo, een onderzoeksgroep die kunstmatige intelligentie steeds meer probeert in te zetten voor de patiëntenzorg. Hij vertelt dat ze eerst bezig waren met de ontwikkeling van een algoritme dat de drukte op de eerste hulp kan voorspellen. ‘Het was daarmee een makkelijke stap om ook met de gegevens over het coronavirus aan de slag te gaan.’

Grote hoeveelheid data
De onderzoeksgroep heeft allerlei publieke data die met het coronavirus te maken hebben verzameld. ‘Dat zijn onder meer gegevens van het RIVM, weer, verkeer en socio-economische data,’ aldus Vlaar.
Al die gegevens maken het lastig om zelf verbanden te leggen. ‘Iedereen kan bedenken dat bij een groot evenement er een toename van drukte in het ziekenhuis is. Het voorspellen van uitbraken van coronavirus is echter zo complex, er is zo veel data bij betrokken, dat je er met één simpele associatie niet komt. Daar komen wij zelf met ons gezonde verstand niet uit. Een computer kan op een gegeven moment aan de hand van alle data wel allerlei associaties maken.’
Een zo goed mogelijk model
Kunstmatige intelligentie biedt dus uitkomst. ‘Heel simpel gezegd, stop je alle verzamelde gegevens in de computer,’ legt Vlaar uit. ‘Je wilt daar een zo goed mogelijk model van maken. Daarom laat je de computer steeds weer trainen met de data van wat er daadwerkelijk gebeurd is.’ Postdoc Björn van der Ster en masterstudent Thijs Spanhaak bouwden zo de tool op.
In Windfall kun je bijvoorbeeld zien dat als je de aantallen per 100.000 inwoners bekijkt, de gemeente Heerde in Gelderland het sterkst getroffen is qua infecties en de gemeente Bernheze in Brabant wat betreft het aantal overledenen.
Verder staat in de grafiekjes een voorspelling weergegeven. Zo voorspelt de tool dat er op 10 juni in totaal rond de 615 coronapatiënten van de gemeente Amsterdam in het ziekenhuis zijn terechtgekomen. Op 7 juni stond dat totaal op 614. Vlaar: ‘De voorspelling gaat drie dagen verder dan de gegevens die we hebben. Als we nog verder voorspellen, wordt de tool minder betrouwbaar.’
Overzicht corona-gegevens miste nog
Hij en zijn collega’s zijn wel trots op deze applicatie, laat hij weten. ‘Dit misten we eigenlijk nog in Nederland: een applicatie waarin je een overzicht van alle gegevens over corona kunt inzien. Hierdoor weet je nu hoe het ervoor staat per regio. Je kunt dit weer toepassen om te bekijken waarom het virus in een bepaalde gemeente meer toeslaat dan in andere. Nu proberen we het verder te koppelen aan bewegingen van mensen, en aan verschillen in maatregelen op lokaal niveau.’
Uiteindelijk wil de onderzoeksgroep deze tool ook in andere landen gaan toepassen. Er zijn al gesprekken gaande met het Verenigd Koninkrijk en Malta. ‘Dan kunnen we straks een kaart van heel Europa maken. Maar eerst proberen we het model continu te verbeteren met de nieuwe data die we er steeds bij krijgen.’
